In the intricate world of AI chatbots and virtual assistants, the integration of advanced Natural Language Processing (NLP) and Natural Language Understanding (NLU) is pivotal for refining user interactions. These technologies enable chatbots to not only comprehend but also retain the context of conversations, closely mimicking human-like interactions.
Intent classification, a cornerstone of NLU within the broader NLP framework, plays a crucial role in interpreting the user’s intent from their interactions. The accuracy of this classification directly influences the virtual assistant effectiveness answering accurately queries asked by the user; inaccuracies can lead to irrelevant responses, thereby impacting the user conversational experience.
The use of BERT in intent classification provides a comprehensive solution by leveraging its capability to process extensive language datasets, thereby significantly enhancing the system’s ability to recognize and classify user intents accurately. This method involves a meticulous training regime that fine-tunes BERT on intent-specific data, substantially boosting its effectiveness in delivering accurate and contextually relevant responses, and thus improving the overall efficacy of virtual assistants and chatbots.
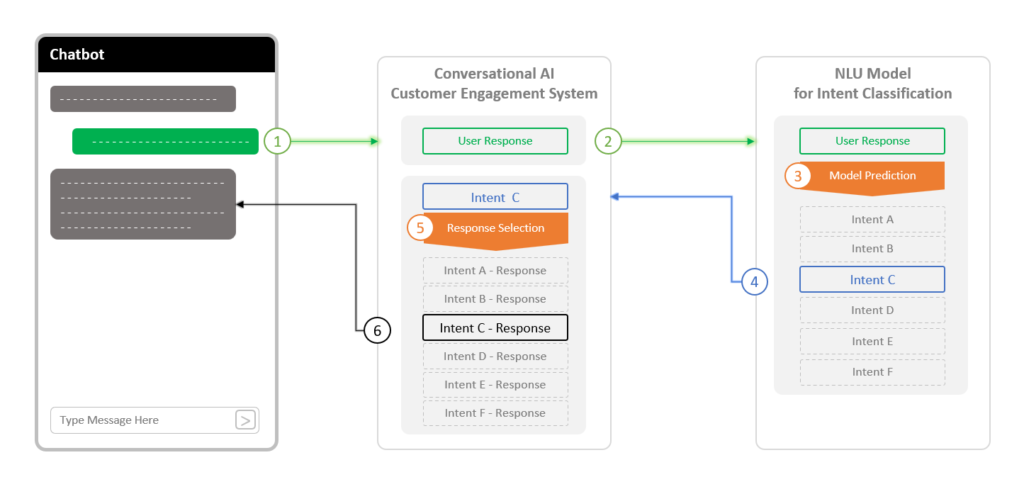
Basic building blocks of a chatbots using NLU
The basic building blocks of a chatbot using NLU, as depicted in the diagram below, involve an interactive cycle between the user and the Conversational AI customer engagement system. (1) When a customer responds, (2) the system channels this input to the NLU model, (3) which then predicts the intent of the user’s message. The model assesses the probability of various intents and (4) relays the most likely one, or a list ranked by confidence levels, back to the AI system. (5) Subsequently, the system interprets this intent to determine the appropriate action, which could range from selecting a response to executing a transaction or automating a process. (6) Finally, the conversational AI communicates the pre-defined response associated with the identified intent back to the customer. This seamless integration of NLU in chatbots ensures a dynamic and contextually aware interaction, closely resembling human conversation.
The article outlines a straightforward approach to training and building a BERT model for intent classification in chatbots, emphasizing that while there are numerous methods for training BERT, the described process offers a foundational understanding. This approach highlights the essential steps from data preparation to model evaluation, providing a basic yet effective framework for implementing BERT in conversational AI applications.
Instructions
The instruction provided below outlines the process of building an NLU multiclass intent classification model using the BERT model with TensorFlow, aimed at enhancing chatbots and virtual assistants functionalities. It is structured in a key steps, starting with loading necessary libraries, followed by data handling (loading, reviewing, preprocessing), model building and training, performance evaluation, and finally, model testing with test data and user input.
Each section is designed to guide the reader through the development of a machine learning model, emphasizing practical aspects like data preprocessing, model training with callbacks like EarlyStopping, and performance visualization through metrics such as accuracy, recall, and precision. This structured approach facilitates understanding and implementation of NLU multi-class intent classification in real-world chatbot and virtual assistant applications.
#1 Loading Necessary Libraries
The initial step in intent classification involves loading essential libraries to manage data, visualize results, perform computations, and implement machine learning models. Key libraries include Pandas and NumPy for data manipulation, Matplotlib and Seaborn for visualization, and various components from Scikit-learn for evaluating model performance. The TensorFlow framework and the Transformers library are crucial for leveraging BERT models in NLP tasks. Additional utilities like callbacks from Keras, random for randomness control, and configuration settings to manage display options and suppress warnings, ensure a smooth development environment. These libraries form the backbone of the project, facilitating data handling, model training, and evaluation processes.
# Import Data Manipulation Libraries
import pandas as pd
import numpy as np
# Import Data visualization Libraries
import matplotlib.pyplot as plt
import seaborn as sns
#To import different metrics
from sklearn import metrics
from sklearn.metrics import (
f1_score,
accuracy_score,
recall_score,
precision_score,
confusion_matrix
)
# Import JSON Library
import json
# Import TensorFlow
import tensorflow as tf
# Import Transformers
from transformers import BertTokenizer, TFBertForSequenceClassification
#Importing classback API
from keras import callbacks
from tensorflow.keras import backend
# Library to avoid the warnings
import warnings
warnings.filterwarnings("ignore")
# To supress scientific notations for a dataframe
pd.set_option("display.float_format", lambda x: "%.2f" % x)
#2 Loading and Reviewing Dataset
Reviewing the dataset before training is pivotal as it ensures data quality and informs preprocessing needs. This process includes examining the dataset’s structure, identifying missing or duplicate entries, and understanding the distribution of unique values. Such an evaluation helps in detecting anomalies or biases that might affect the model’s performance, guiding necessary cleaning and normalization steps to enhance data integrity. Ensuring a well-structured and clean dataset is foundational for building reliable and accurate machine learning models, particularly in intent classification where the subtleties of language data are crucial.
# Import drive to load training data file
from google.colab import drive
drive.mount('/content/drive/')
# Path to train data file
train_data_file_path = '/content/drive/My Drive/aiml/intent_classification/train_data.json'
# Open and read the JSON file
with open(train_data_file_path, 'r') as file:
json_data = json.load(file)
# Convert the JSON train data to a pandas DataFrame
train_data = pd.DataFrame(json_data, columns=['text', 'label'])
# View the first 5 rows of the dataset
train_data.head()
text label
0 what expression would i use to say i love you ... translate
1 can you tell me how to say 'i do not speak muc... translate
2 what is the equivalent of, 'life is good' in f... translate
3 tell me how to say, 'it is a beautiful morning... translate
4 if i were mongolian, how would i say that i am... translate
# View the last 5 rows of the dataset
train_data.tail()
text label
14995 can you explain why my card was declined card_declined
14996 how come starbucks declined my card when i tri... card_declined
14997 how come my card was not accepted yesterday card_declined
14998 find out what happened to make my card get dec... card_declined
14999 why was my card declined at safeway card_declined
# View the shape of the dataset
train_data.shape
(15000, 2)
# View the data types of the columns
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15000 entries, 0 to 14999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 15000 non-null object
1 label 15000 non-null object
dtypes: object(2)
memory usage: 234.5+ KB
# Checking for unique values
train_data.nunique()
text 15000
label 150
dtype: int64
# Checking for Duplicate Entries
train_data.duplicated().sum()
0
# Checking for Missing Values
train_data.isna().sum()
text 0
label 0
dtype: int64
#3 Preprocessing data
Preprocessing data involves transforming raw text into a format that the BERT model can understand. This step includes splitting the dataset into input texts and their corresponding target labels.
# Extract intent labels and text data
# used as the input variables for the model
train_text = train_data['text']
# used as the target variable for predicting the intent
train_label = train_data['label']
Map intents to numerical labels
# Cconvert categorical labels (intent labels, in this case) into numerical values
unique_intents = train_label.unique()
intent_to_label = {intent: i for i, intent in enumerate(unique_intents)}
# Inverse the intent_to_label mapping to create a label_to_intent mapping (to be used later on for prediction)
label_to_intent = {label: intent for intent, label in intent_to_label.items()}
# The target variable = labels in numberical values
train_label_y = [intent_to_label[intent] for intent in train_label]
# Convert labels (intent numberical labels) to TensorFlow tensors
train_label_y = tf.convert_to_tensor(train_label_y)
#4 Tokenizing the Input Data
For the BERT model, input texts are tokenized into tokens that match the model’s pre-training, converted to input ids, and organized with attention masks to differentiate actual content from padding. This process ensures that the model receives input in a structured form, optimizing its ability to learn from and accurately classify text data according to the defined intents.
Tokenizing the training data
# Load the BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Tokenize the training texts
train_encodings = tokenizer(train_text.tolist(), truncation=True, padding=True, max_length=128, return_tensors='tf')
# Prepare Input Data for Bert Model
train_input_data = {
'input_ids': train_encodings['input_ids'],
'attention_mask': train_encodings['attention_mask']
}
Loading and Tokenizing the Validation Data
# Path to train data file
valid_data_file_path = '/content/drive/My Drive/aiml/intent_classification/valid_data.json'
# Open and read the JSON file
with open(valid_data_file_path, 'r') as file:
json_data = json.load(file)
# Convert the JSON data to a pandas DataFrame
valid_data = pd.DataFrame(json_data, columns=['text', 'label'])
# Extract intent labels and text data
valid_label = valid_data['label']
valid_text = valid_data['text']
# Map intents to numerical labels
# convert categorical labels (intent labels, in this case) into numerical values
unique_intents = valid_label.unique()
intent_to_label = {intent: i for i, intent in enumerate(unique_intents)}
valid_label_y = [intent_to_label[intent] for intent in valid_label]
print('There are',len(intent_to_label),'labels')
# Convert labels (intent numberical labels) to TensorFlow tensors
valid_label_y = tf.convert_to_tensor(valid_label_y)
# Tokenize the training texts
valid_encodings = tokenizer(valid_text.tolist(), truncation=True, padding=True, max_length=128, return_tensors='tf')
# input data for the model
valid_input_data = {
'input_ids': valid_encodings['input_ids'],
'attention_mask': valid_encodings['attention_mask']
}
#5 Building and Training model
Building and training the model involves tokenizing input data using BertTokenizer as shown above, which adapts text for BERT’s understanding. The model, TFBertForSequenceClassification, is initialized with pretrained weights (‘bert-base-uncased’) to leverage prior knowledge. It’s compiled with the Adam optimizer and SparseCategoricalCrossentropy loss, focusing on accuracy as the key metric. EarlyStopping is employed to prevent overfitting by halting training when validation loss ceases to decrease, enhancing model generalization. The training process, governed by hyperparameters like batch size and epochs, is crucial for minimizing loss and maximizing accuracy, with potential adjustments in hyperparameters aiding in refining model performance.
Pre-trained BERT model for sequence classification with Adam Optimizer
# Load the pre-trained BERT model for sequence classification
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=len(intent_to_label))
# using Adams optimized with learning rate 1e-5
optimizer = tf.keras.optimizers.Adam(learning_rate=0.00001)
# using SparseCategoricalCrossentropy as loss function used in multi-class classification problems.
# The "Sparse" in SparseCategoricalCrossentropy indicates that the labels are provided as integers (e.g., [0, 2, 1...] for three classes),
# as opposed to one-hot encoded arrays.
# from_logits=True, the SparseCategoricalCrossentropy loss function internally applies a softmax function to the logits before computing the actual loss value.
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# Compiling the model with the optimizer, loss func and metrics
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
# Obtain the summary of the model
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (TFBertMainLayer) multiple 109482240
dropout_37 (Dropout) multiple 0
classifier (Dense) multiple 115350
=================================================================
Total params: 109597590 (418.08 MB)
Trainable params: 109597590 (418.08 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
EarlyStopping
During training, the model is evaluated on a holdout validation dataset after each epoch. If the performance of the model on the validation dataset starts to degrade or no improvement (e.g. loss begins to increase or accuracy begins to decrease), then the training process is stopped after certain iterations. The model at the time that training is stopped is then used and is known to have good generalization performance.
es_cb = callbacks.EarlyStopping(monitor='val_loss', min_delta=0.01, patience=5)
Training the Model
The fit command in TensorFlow trains the model on the specified training data and labels, evaluates its performance on validation data across a defined number of epochs, and applies callbacks like EarlyStopping to monitor and enhance training efficiency.
# Train the model
history = model.fit(
train_input_data,
train_label_y,
validation_data=(valid_input_data,valid_label_y),
epochs=7,
batch_size=32,
callbacks=[es_cb]
)
Epoch 1/7
469/469 [==============================] - 219s 296ms/step - loss: 4.5624 - accuracy: 0.1529 - val_loss: 3.8745 - val_accuracy: 0.5263
Epoch 2/7
469/469 [==============================] - 134s 286ms/step - loss: 3.3931 - accuracy: 0.6974 - val_loss: 2.7528 - val_accuracy: 0.8353
Epoch 3/7
469/469 [==============================] - 127s 271ms/step - loss: 2.3830 - accuracy: 0.8890 - val_loss: 1.8424 - val_accuracy: 0.9130
Epoch 4/7
469/469 [==============================] - 127s 270ms/step - loss: 1.5628 - accuracy: 0.9477 - val_loss: 1.1744 - val_accuracy: 0.9450
Epoch 5/7
469/469 [==============================] - 127s 270ms/step - loss: 0.9767 - accuracy: 0.9728 - val_loss: 0.7457 - val_accuracy: 0.9583
Epoch 6/7
469/469 [==============================] - 126s 269ms/step - loss: 0.6000 - accuracy: 0.9874 - val_loss: 0.4953 - val_accuracy: 0.9607
Epoch 7/7
469/469 [==============================] - 126s 269ms/step - loss: 0.3743 - accuracy: 0.9929 - val_loss: 0.3626 - val_accuracy: 0.9653
#6 Visualizing Training Process and Results
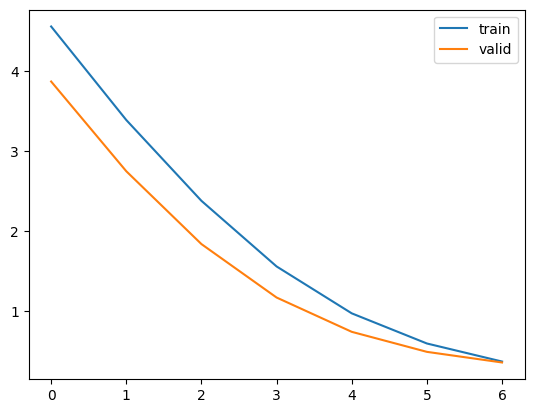
Visualizing the training process through loss and accuracy plots is critical in machine learning. These plots offer insights into the model’s learning trajectory over epochs, helping to identify patterns such as overfitting or underfitting. By examining these trends, developers can make informed decisions about adjusting model parameters or training strategies to enhance performance and ensure the model generalizes well to unseen data
Loss Function
# Capturing learning history per epoch and displaying it
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
# Plotting accuracy at different epochs
plt.plot(hist['loss'])
plt.plot(hist['val_loss'])
plt.legend(("tin" , "valid") , loc =0)
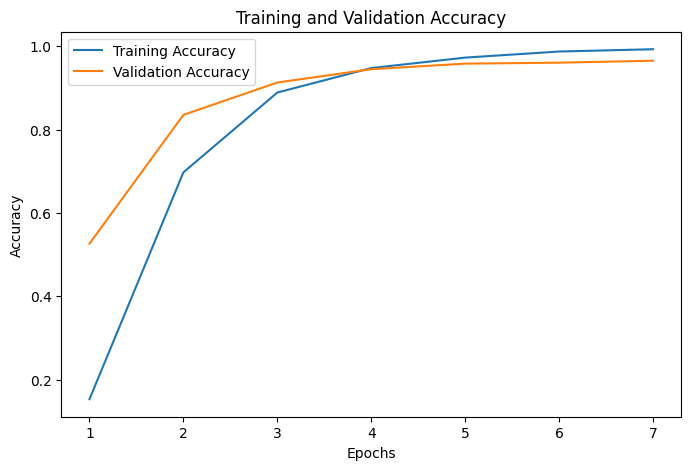
Training and Validation Accuracy
# 'history' is the result from model.fit()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
# Plotting training and validation accuracy
plt.figure(figsize=(8, 5))
plt.plot(epochs, acc, label='Training Accuracy')
plt.plot(epochs, val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
#7 Loading and preprocessing the test data
Loading and preprocessing the test dataset before generating predictions is essential to ensure the data aligns with the model’s training format. This involves tokenizing the test’s text data, converting it to the format expected by BERT, and adjusting the input dimensions to match the model’s requirements. Proper preprocessing guarantees that the model accurately interprets the input data, leading to reliable predictions.
# Path to train data file
test_data_file_path = '/content/drive/My Drive/aiml/intent_classification/test_data.json'
# Open and read the JSON file
with open(test_data_file_path, 'r') as file:
json_data = json.load(file)
# Convert the JSON data to a pandas DataFrame
test_data = pd.DataFrame(json_data, columns=['text', 'label'])
# Extract intent labels and text data
test_label = test_data['label']
test_text = test_data['text']
# Map intents to numerical labels
# convert categorical labels (intent labels, in this case) into numerical values
unique_intents = test_data['label'].unique()
intent_to_label = {intent: i for i, intent in enumerate(unique_intents)}
test_label_y = [intent_to_label[intent] for intent in test_label]
# Convert labels (intent numberical labels) to TensorFlow tensors
test_label_y = tf.convert_to_tensor(test_label_y)
# Tokenize the training texts
test_encodings = tokenizer(test_text.tolist(), truncation=True, padding=True, max_length=128, return_tensors='tf')
# Prepare the input data for the model
test_input_data = {
'input_ids': test_encodings['input_ids'],
'attention_mask': test_encodings['attention_mask']
}
#8 Generating Predictions
Generating predictions on the test dataset involves using the trained model to evaluate unseen data, translating the model’s logits to probabilities for interpretability, and finally, mapping these probabilities to class labels. This process is crucial for assessing the model’s performance in real-world scenarios, ensuring its ability to accurately classify new, unobserved inputs.
# Generate predictions
test_predictions = model.predict(test_input_data)
# `test_predictions` is a TFSequenceClassifierOutput object
logits = test_predictions.logits
# Convert logits to probabilities (optional, for better interpretability)
probabilities = tf.nn.softmax(logits, axis=-1)
# Convert probabilities to class labels
test_pred_labels = tf.argmax(probabilities, axis=-1)
141/141 [==============================] - 14s 77ms/step
#9 Evaluating model performance
Evaluating model performance on test data using metrics like recall, precision, accuracy, and F1 score is crucial. These metrics provide a comprehensive view of the model’s ability to correctly classify intents, balance between sensitivity and specificity, and maintain overall effectiveness across various classes. High performance in these areas indicates a model well-tuned to handle real-world scenarios, making it a reliable component in chatbot systems for accurately interpreting and responding to user queries.
# To supress scientific notations for a dataframe
pd.set_option("display.float_format", lambda x: "%.3f" % x)
def model_performance_classification(target,pred):
# Calculate accuracy
accuracy = accuracy_score(target, pred)
# Calculate precision
precision = precision_score(target, pred, average='weighted', zero_division=0)
# Calculate recall
recall = recall_score(target, pred, average='weighted', zero_division=0)
# Calculate F1 score
f1 = f1_score(target, pred, average='weighted', zero_division=0)
# creating a dataframe of metrics
df_perf = pd.DataFrame(
{
"Accuracy": accuracy,
"Recall": recall,
"Precision": precision,
"F1": f1
},
index=[0],
)
return df_perf
model_performance = model_performance_classification(test_label_y,test_pred_labels)
model_performance
Accuracy Recall Precision F1
0.959 0.959 0.961 0.959
#10 Predicting Intent of User Input
The final step involves applying the trained model to predict the intent of user-provided text, showcasing the model’s real-world applicability. This critical phase validates the model’s capability to accurately interpret and classify new inputs, reflecting its effectiveness in understanding and responding to user queries within a chatbot framework.
input_text = ['I would need 5 days for my vacation']
# Tokenize the input text text
input_text_encodings = tokenizer(input_text, truncation=True, padding=True, max_length=128, return_tensors='tf')
input_text_input_data = {
'input_ids': input_text_encodings['input_ids'],
'attention_mask': input_text_encodings['attention_mask']
}
# Generate predictions
input_text_predictions = model.predict(input_text_input_data)
# input_text_predictions is a TFSequenceClassifierOutput object
logits = input_text_predictions.logits
# Convert logits to probabilities (optional, for better interpretability)
probabilities = tf.nn.softmax(logits, axis=-1)
# Convert probabilities to class labels
input_text_pred_labels = tf.argmax(probabilities, axis=-1)
# Inverse the intent_to_label mapping to create a label_to_intent mapping
# label_to_intent = {label: intent for intent, label in intent_to_label.items()}
# Convert the predicted label indices to numpy if they aren't already
input_text_pred_labels_np = input_text_pred_labels.numpy()
# Map the numerical label to its corresponding intent using the inverse mapping
predicted_intents = [label_to_intent[label] for label in input_text_pred_labels_np]
print("Predicted intents:", predicted_intents)
1/1 [==============================] - 3s 3s/step
Predicted intents: ['pto_request']
Summary
The article guides through building a multi-class intent classification model using BERT for chatbots and virtual assistants, covering essential steps from loading libraries, data review, preprocessing, model training, to evaluation. It emphasizes the significance of each phase in enhancing chatbot interactions through accurate intent classification, ensuring a seamless user experience. While there are numerous methods for training BERT, the described process offers a foundational understanding only.