Introduction
In today’s rapidly evolving digital landscape, customer engagement is paramount for business success. Leveraging generative AI to automate and personalize responses based on customer intent can significantly enhance user experience. A hybrid approach that combines predefined responses, generative responses, and Retrieval-Augmented Generation (RAG) technology helps in minimizing hallucinations, ensuring accuracy, and delivering contextually appropriate answers. This article explores an advanced system for responding to user queries based on identified customer intents, detailing how it integrates various response mechanisms to optimize interaction.
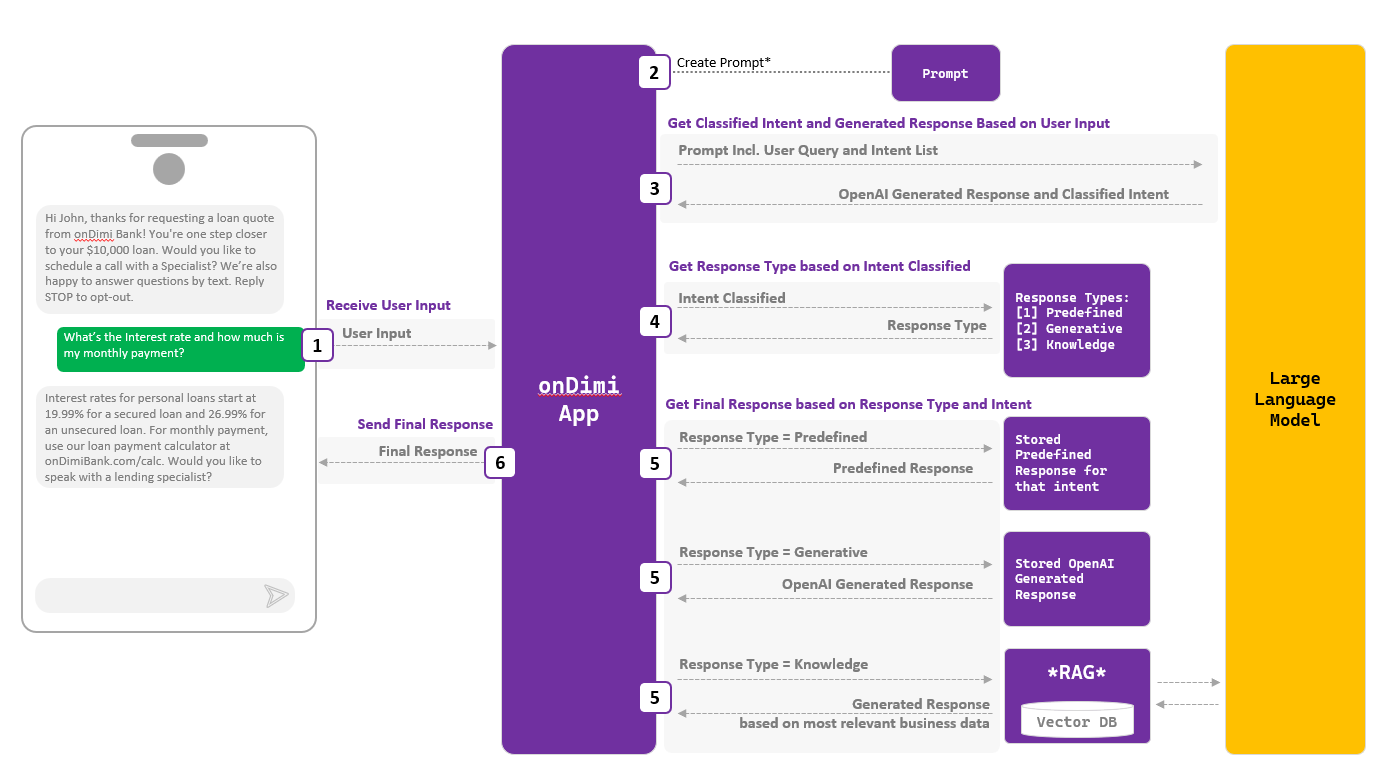
Intent-Based Response Generation Steps
1) Receive User Input:
The process begins when the user sends a query. For instance, a customer might ask, “What’s the interest rate and how much is my monthly payment?”
2) Create an Effective Prompt (Prompt Engineering):
Craft a prompt based on the use case, incorporating the specific use case prompt, a list of intents to be classified, the user’s input, and the conversation history between the user and the virtual assistant.
3) Generate Response and Classify Intent:
The system captures the user’s query and sends it to the AI app. Here, an API call is made to the LLM, including the user’s query and a list of predefined intents.
The LLM classifies the intent from the list and generates a preliminary response. For example, if the user asks about loan rates, the LLM identifies the intent as ‘loan interest inquiry’ and generates a relevant response.
4) Determine Response Type:
Once the intent is classified, the system determines the response type based on response type rules. There are three main types of responses:
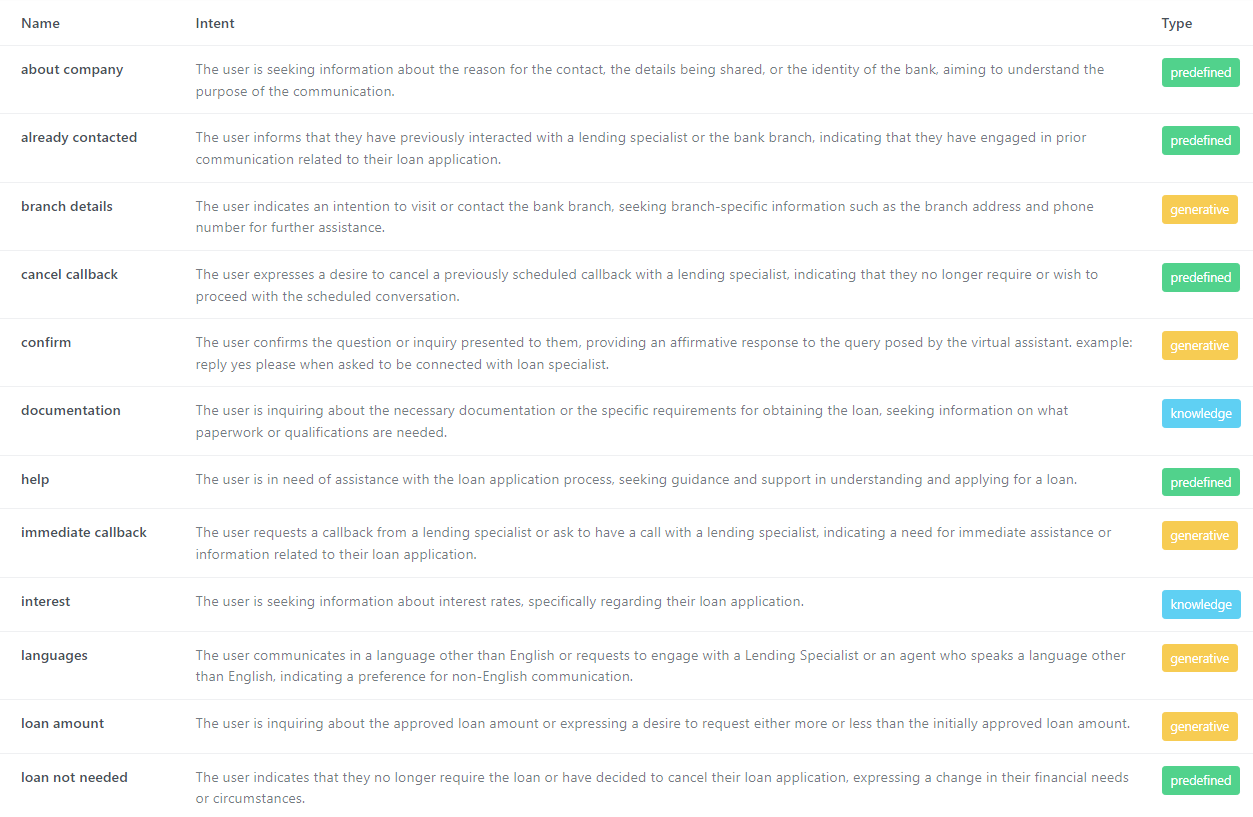
Predefined Response: For common queries with well-established answers, a predefined response is used. This ensures accuracy and consistency.
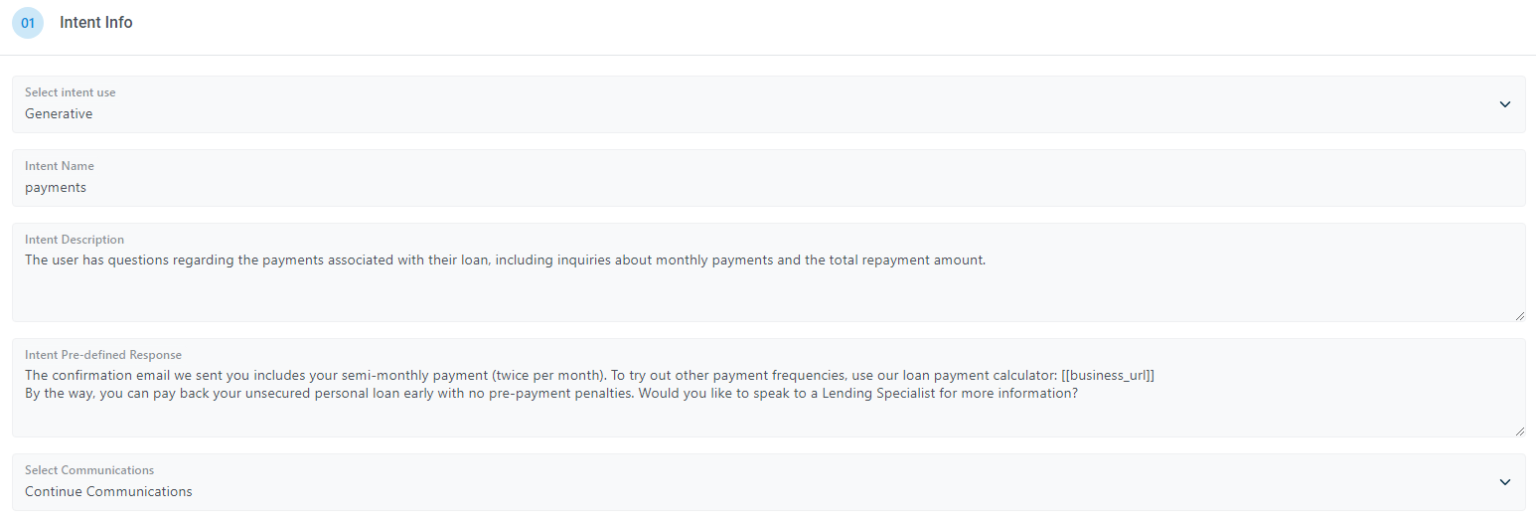
Generative Response: When the LLM is proficient in generating contextually accurate and dynamic responses for specific intents, the generated response is utilized directly.
Knowledge Base Response: For complex or business-specific queries, the system employs RAG technology. It queries a vector database to find the most relevant information and then uses the LLM to generate a refined response based on this data.
5) Retrieve The Finalize Response:
Depending on the identified response type, the system retrieves the appropriate response.
Predefined Response: The system pulls the response from a stored set of predefined replies.
Generative Response: The previously generated response by the LLM is used.
Knowledge Base Response: The system queries the knowledge base for relevant information, and the LLM refines this data to create a final response.
6) Fetch the Final Response
The final response is then sent to the user through the onDimi app, ensuring that the customer receives accurate and relevant information promptly.
Importance of Using RAG and Predefined Responses
Integrating RAG and predefined responses into customer interaction systems reduces the risk of hallucinations—incorrect or irrelevant responses generated by AI. Predefined responses ensure that commonly asked questions are answered consistently and accurately, while RAG leverages vast amounts of business-specific data to provide precise and contextually appropriate answers. This hybrid approach optimizes the strengths of generative AI while mitigating its weaknesses, leading to a more reliable and effective customer service experience.
By following this structured approach, businesses can enhance their customer engagement, ensuring that users receive accurate, timely, and contextually relevant responses, ultimately leading to higher satisfaction and trust in the automated systems.